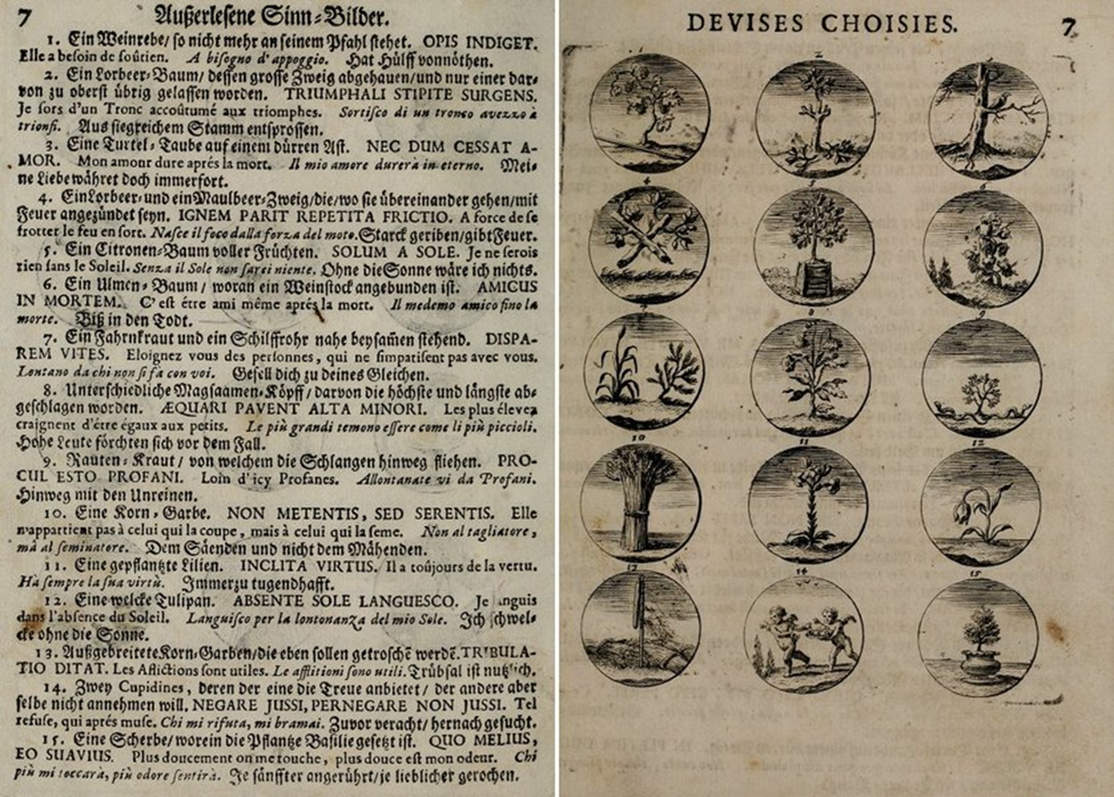
How widespread were the emblem symbols for God? How many places were they published in? How many languages were they written in, and thus how many potential audiences could they have reached? How long did they last? My answer to these questions, based on the data, was that it was typical for a God-signifier, as indicated by an Iconclass notation, to be multilingual and pan-European, rather than limited to a single tongue or present-day nation. As shown in Part 2, within this set of emblems, German, Latin and French dominate as the most frequently used languages…
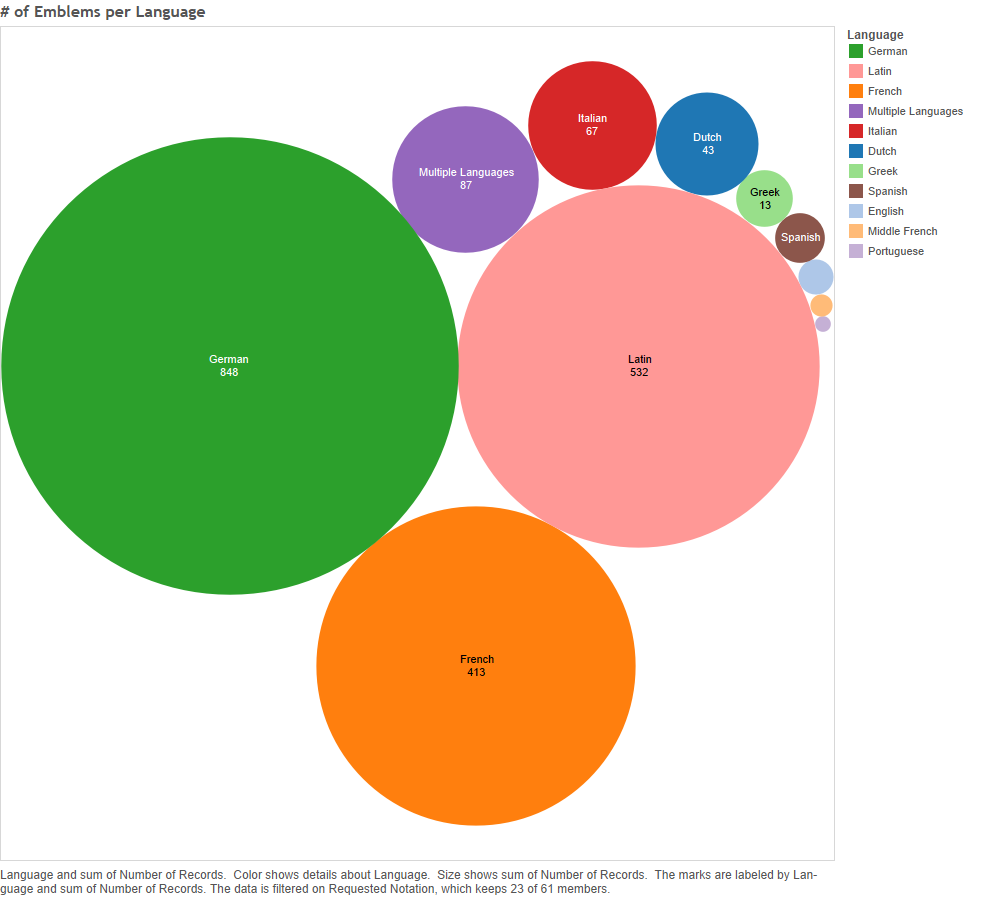
Figure 1 – Number of emblems per language. (Please click on any visualisation to open a larger version in another tab.)
… and Germany is the region that dominates the publication of these emblems, France being a distant second.
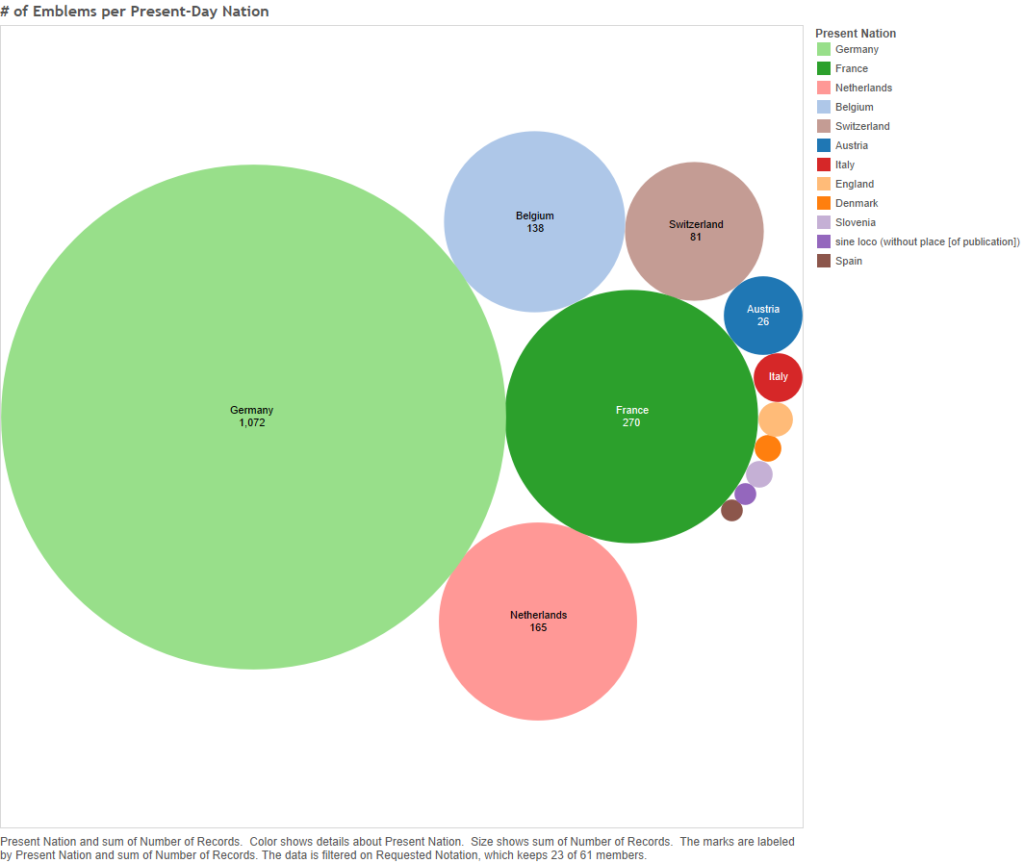
Figure 2 – Number of emblems per present-day nation
Additionally, the symbols last quite a while, on average 135 years between first and final appearances, though very few of the signifiers do so without one or more twenty-year gaps between instances.
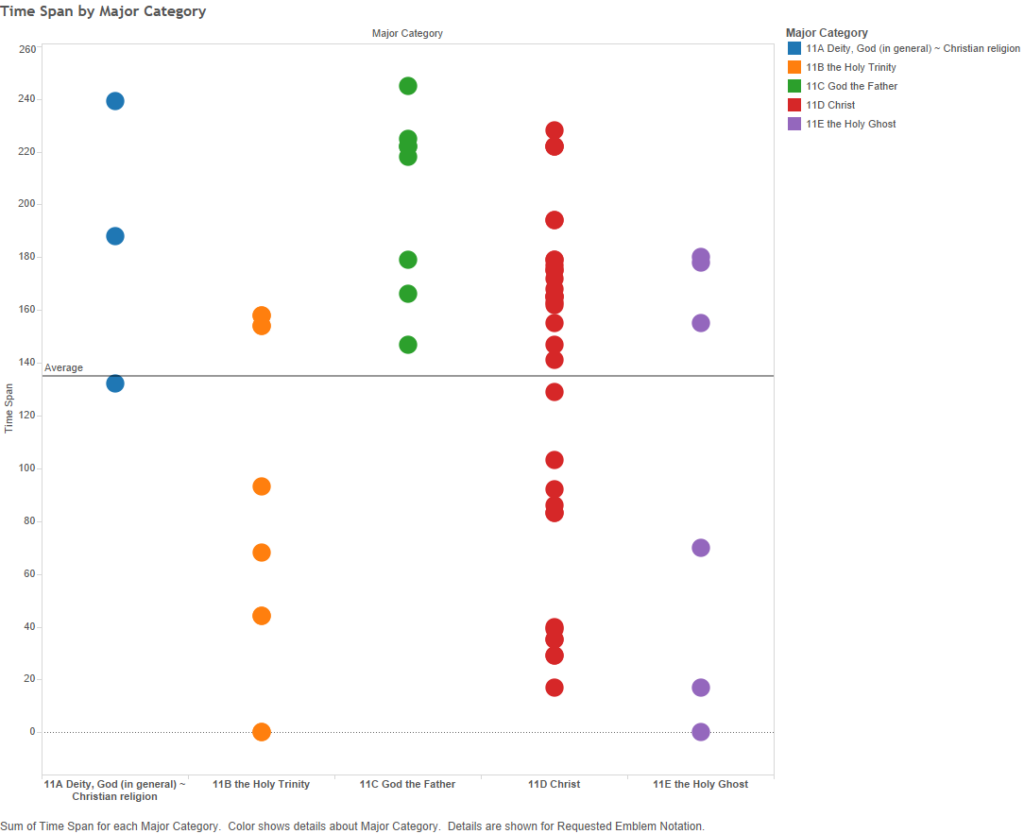
Figure 3 – Time span by major category. Each dot represents the time span for one of the God-symbol notations, from the first emblem published in the dataset to the the last one.
By and large, then, the Christian symbols for God found in the Emblem books tended to be popular, showing at least moderate levels of cultural diffusion, in terms of time, place, and language. This post will discuss the typical cultural extension shown by most of the notations; while still focusing on the odd exceptions to the norm, as those could lead to further research. I will begin by reviewing my method, then I will look at the dimension of time, followed by language and location. Lastly, I will look at the notation for the “Hand of God”, 11C12, as a test of what can be observed in the data of a single symbol. After all, the cultural diffusion of each symbol will depend on its individual publication history as revealed in the data, even if the data averages can tell us what is typical for the whole set of notations.
Method
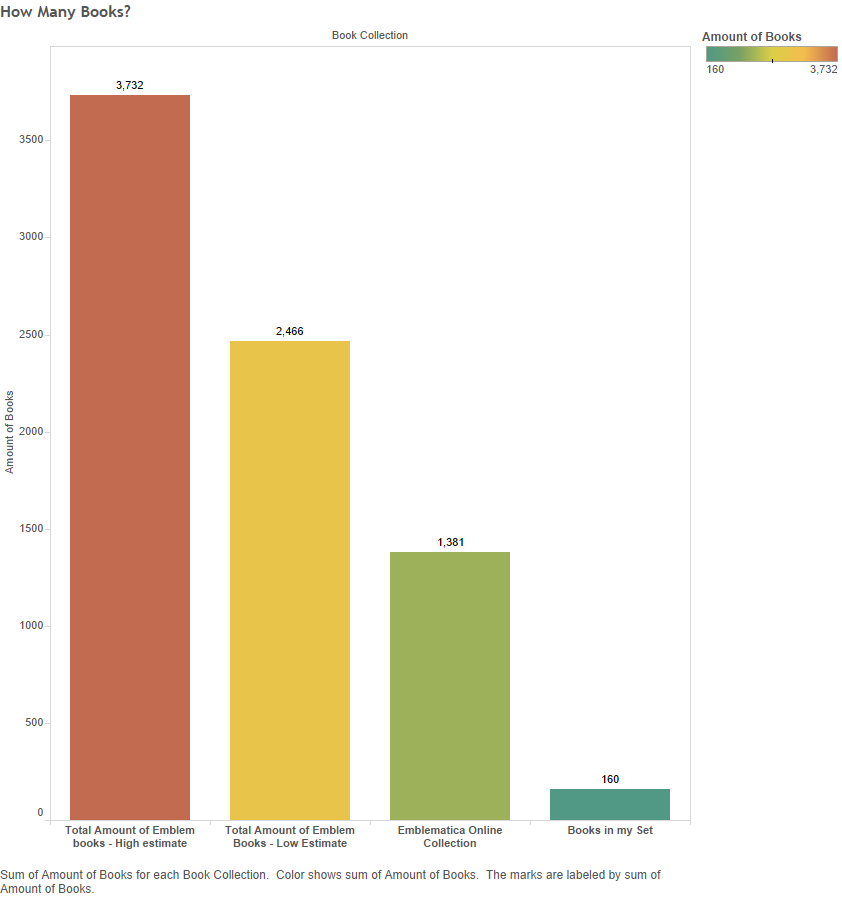
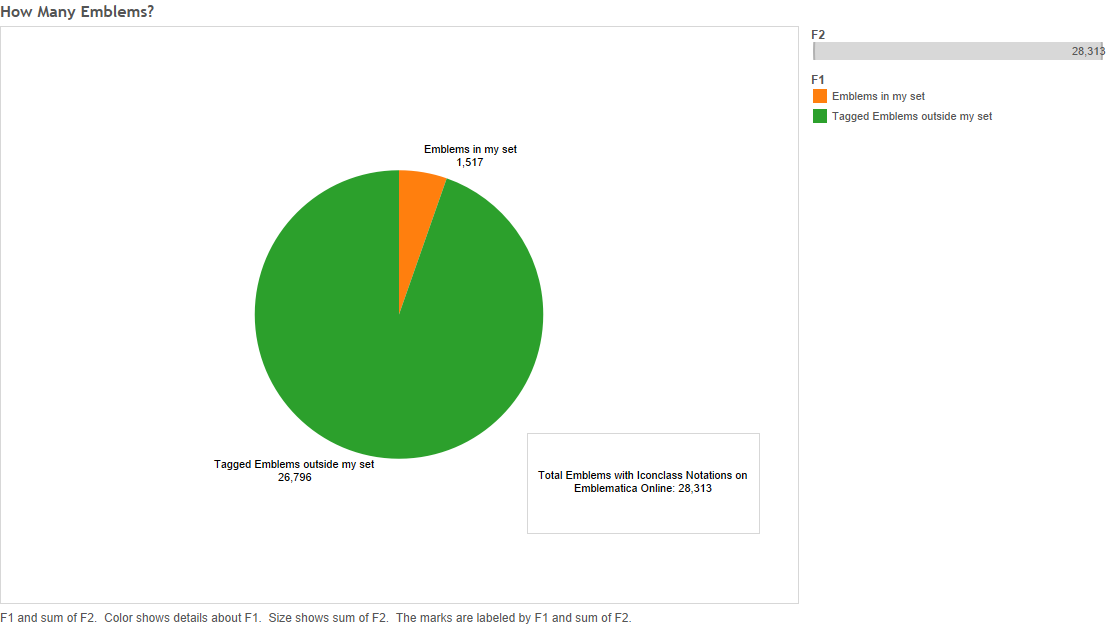
My dataset of bibliographical metadata for 1,517 emblems is organised into sixty-one categories and subcategories based on the Iconclass notations I decided to focus upon. Each category, labelled with an Iconclass notation, includes all emblems tagged with notations that begin with the label, thereby capturing emblems belonging to subcategories further down the Iconclass hierarchy. For example, the dataset for 11C1 includes all the emblems tagged 11C11, 11C12, 11C13, etc. along with those tagged 11C1 itself. The sixty-one categories fall into the following five major Iconclass divisions, in the following amounts:

Figure 4 – Requested notations per major category
Some of the notations, such as “11A3 God’s wrath” denote an abstract notion without specifying a signifier; thus, while I will be using ‘symbol’, ‘signifier’ and ‘notation’ interchangeably below, in some cases there may not be a single symbol for a notation; the notation indicating a type of signifier for a particular signified concept, instead.
Using Iconclass, I examined visualisations for each of the sixty-one categories, showing the number of emblems published in each location and each year, and in what language. As an example, the following few visualisations show the data results for emblems tagged with notations beginning with “11E541”, which denotes Wisdom as a gift of the Holy Ghost (forty-three emblems in set).
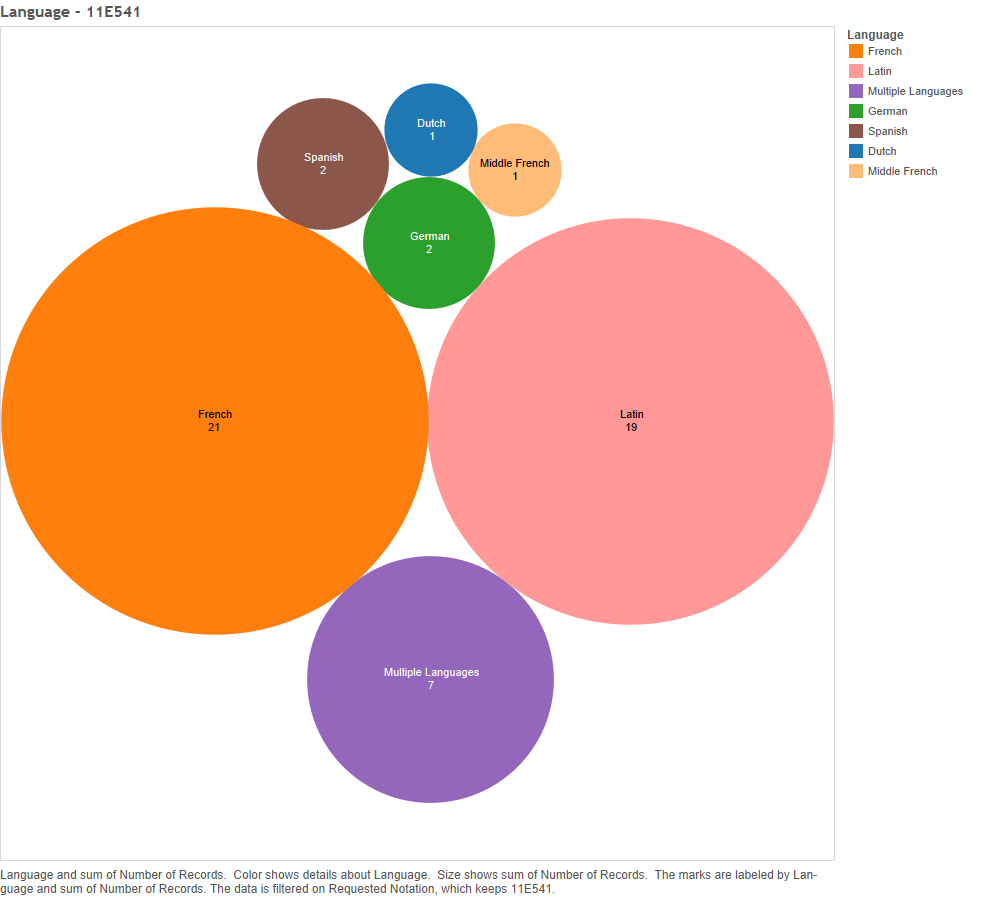
Figure 5 – 11E541: Number of emblems per language

FIgure 6 – 11E541: Number of emblems per present-day nation
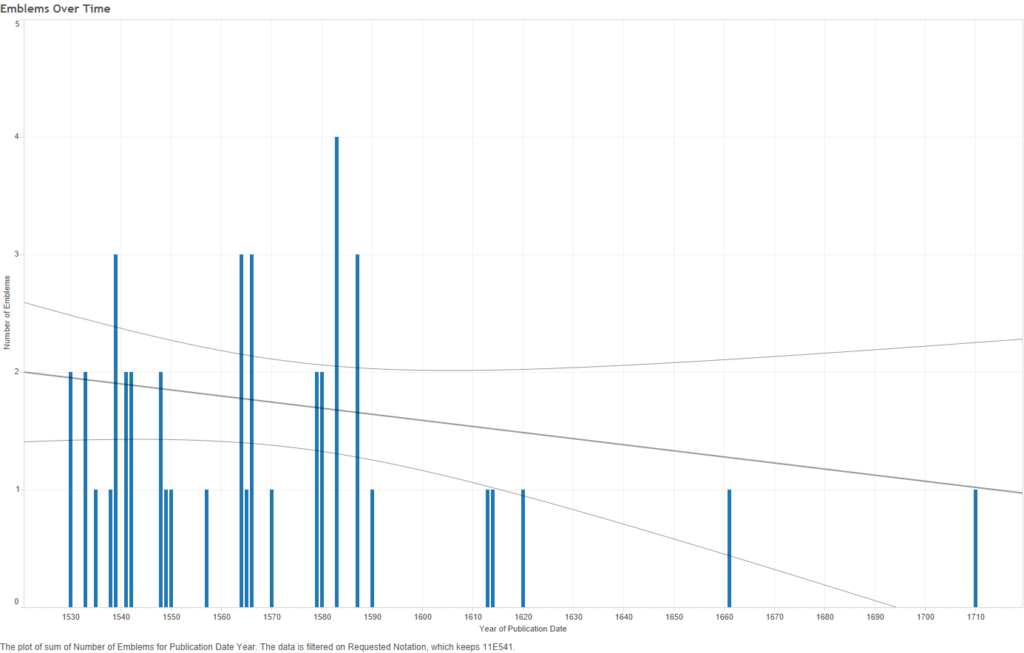
Figure 7 – 11E541: number of emblems over time
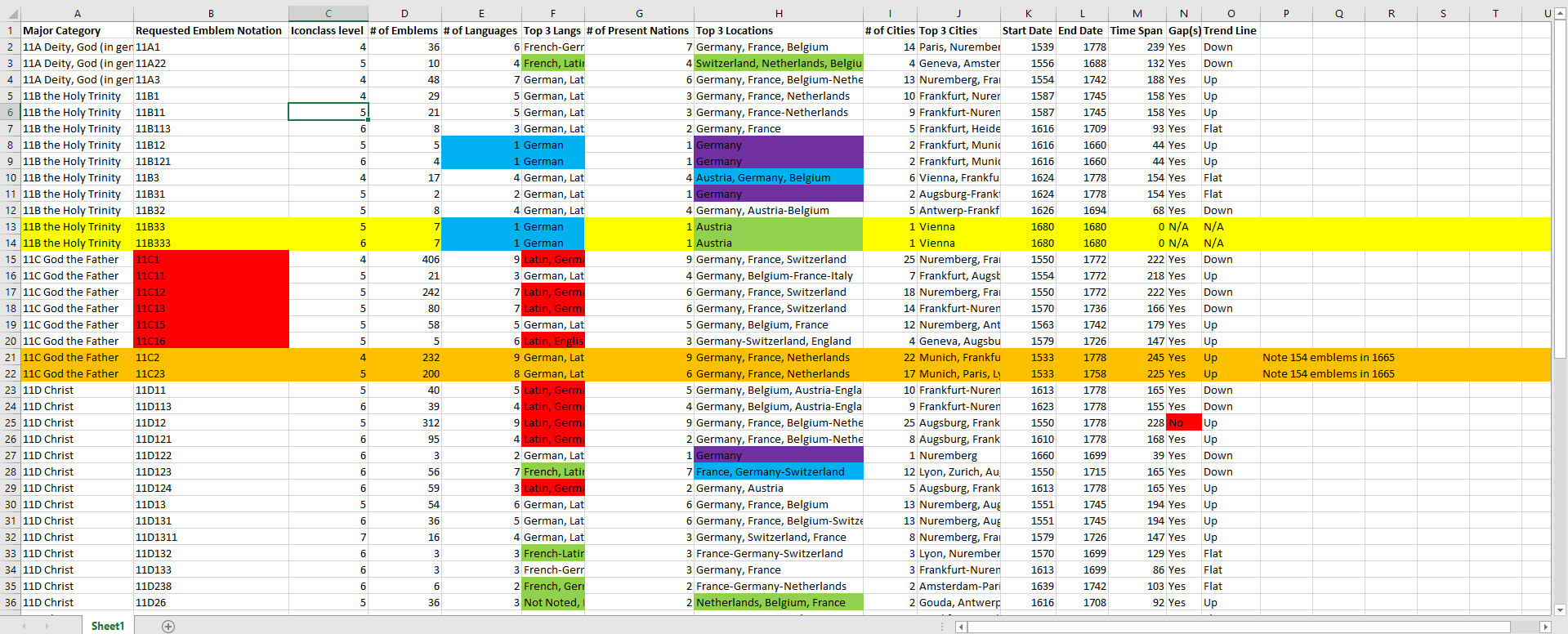
While examining these visualisations, and others, I manually inputted the following information for each category: the category’s title (same as requested notation); the major category (11A to 11E); the level in the Iconclass hierarchy; number of emblems; the top three languages and locations (both by present nation and city – as mentioned in the last post, this was done to standerdise the names and conceptualise the regions that published emblems); total number of languages, nations and cities; the start date (first year the symbol appears); end date (last year the symbol appears); time span between the start and end; a yes/no indicating if there is a gap of over twenty years between emblem appearances of that symbol; and a note of the amount-of-emblems-published trend line (down=decreased over time, up=increased, flat=no change). The below shows a portion of the spreadsheet.
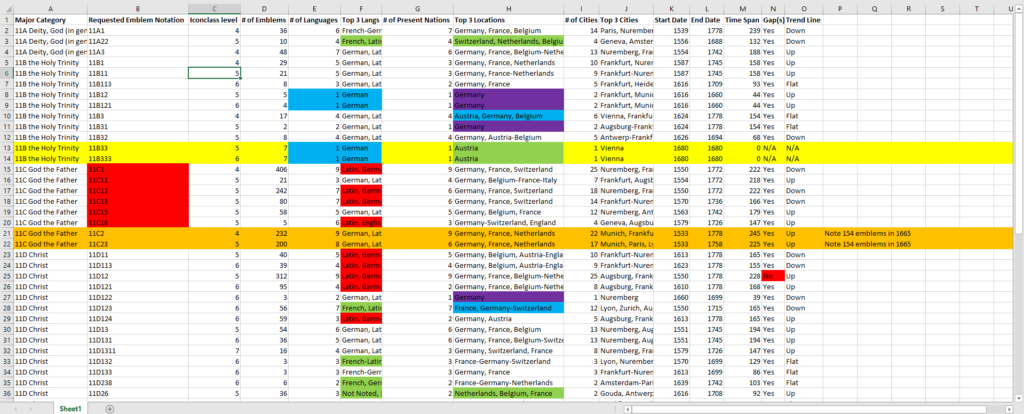
Figure 8 – A portion of the Excel spreadsheet tracking data for each God-symbol category. Colours were used to mark areas of interest to me, and have no impact on the data itself.
So I could give a general overview of the God-signifiers, I imported that spreadsheet into Tableau, and made some graphs looking mostly at time, language and location.
God Emblems Over Time
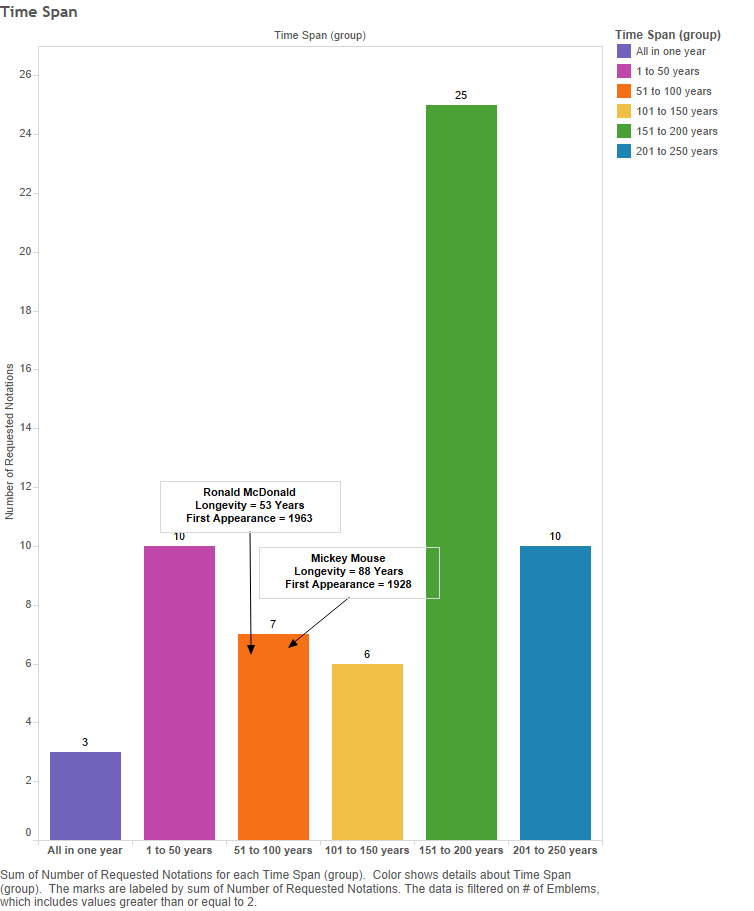
FIgure 9 – Number of God-symbols per time span
The above bar graph shows the longevity of the sixty-one symbols in emblem books. Each bar indicates a total “life span” of a symbol, from first emblem appearance to last emblem appearance. The Y-axis (and the numbers above each bar) indicates how many symbols lasted that long. So we can see, for example, that seven of the signifiers lasted between 51 to 100 years, and that twenty-five signifiers have a longer “life” of somewhere between 151 to 200 years. Since “Emblematic pictures form[ed] part of an iconographic language understood by a wide readership” (Knapp and Tüskés 12), for comparisons sake, I have annotated the graph to show two present day widely recognised corporate icons, Ronald McDonald and Mickey Mouse, who currently would be comparable to those symbols in the 51 to 100-year life-span range (though they are not finished yet). The comparison may be unfair because Ronald and Mickey have the advantage of appearing in multiple media, whereas my data only covers emblem book appearances, neglecting the existence of the same symbol in other art forms. Still, since arguably Mickey and Ronald are long lived, one could separate the bars above into three groups, with two bars to a group. There are thirteen short-lived (1 to 50 years) emblem God-symbols or about 21% of the total. Thirteen symbols have a long life (51 to 150 years); about another 21%. About 57% of the symbols have a very long life of 151 to 250 years. While there is certainly variability in life-span, the symbols generally last for quite a while.
The still-born symbols: Three notations only have emblems in one year. “11E51 the seven gifts of the Holy Ghost represented as seven doves” occurs in two emblems, from two books published in 1551, both by Barthélémy Aneau, one in French and one in Latin. It seems safe to say that, with the present data, that symbol is unique to him within emblem books. It could change as more emblems are marked-up, of course. Similarly, there are seven emblems from a single book published in Vienna, Austria in 1681; that form the entirety of “11B33” and its subcategory “11B333”, the other two notations in the “All in one year” bar. 11B33 vaguely refers to “representations of the Trinity”; 11B333 specifies it as “representation of the Trinity: symbol (Father), person (Son), dove (Holy Ghost)”. With the current dataset, that particular signifier did not make it outside of that one book. The data itself does not give any clear indication why either of these representations did not catch on within emblem books. At present, we simply have to conclude they were just not widespread.
Gaps: While the God-symbols tend to be long lived, that does not mean that they were constantly published within their life spans. The below graph shows the data for “11C13 tetragram (in Roman or Hebrew script) ~ symbol of God the Father”[1] and its subcategories. The x-axis shows the year of publication, and the height of the bars indicate how many emblems that include the four-letter name of God were published each year; the largest being ten emblems in 1699.
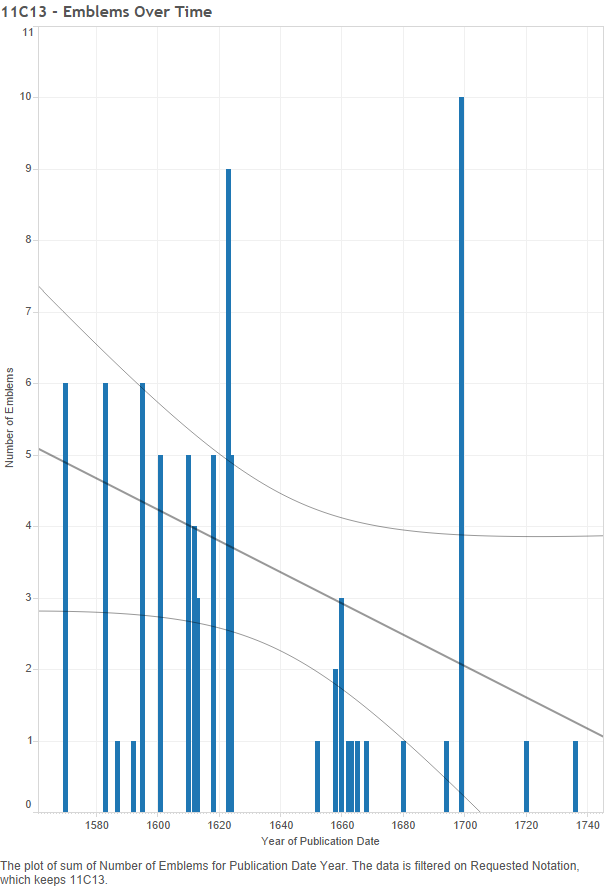
Figure 10 – 11C13: Number of emblems over tIme
As one can see, there are several large gaps where the symbol “disappears” because it was not published in any books within the dataset. This is actually typical of all the notations. Out of fifty-eight Iconclass notations (excluding the three notations which occur only in one year), only five notations do not have one or more gaps over twenty years long. Either the gaps will be filled in as more emblems are tagged, or it is typical for the God-symbols to hibernate and reappear later. Either way, the gaps do not harm the argument that these symbols were long-lasting or culturally diffuse, simply because they came back after periods of absence. Still, the gaps could indicate a shift of focus to other topics, or a wane in a specific symbol’s popularity.
The few without gaps: As stated, there are five notations without one or more gaps of over twenty years between publication. These five separate into two groups. The first group contains two notations which have a life span of less than twenty years (both lasting seventeen years), therefore being unable to have a gap of twenty years. These two symbols – “11D323 Christ-‘Logos’, the Word Incarnate” and “11E2 Holy Ghost represented as flames” – are not long-lived given the data; perhaps they just did not catch on with emblematists and their audiences. The more interesting group, however, is the one made up of three notations (including subcategories): “11D12 the cross ~ symbols of Christ”, “11D326 ‘Fons Vitae’, ‘Fons Pietatis’” [Christ as ‘the fountain of life’], and “11D5 mystic ideas ~ Christ”.
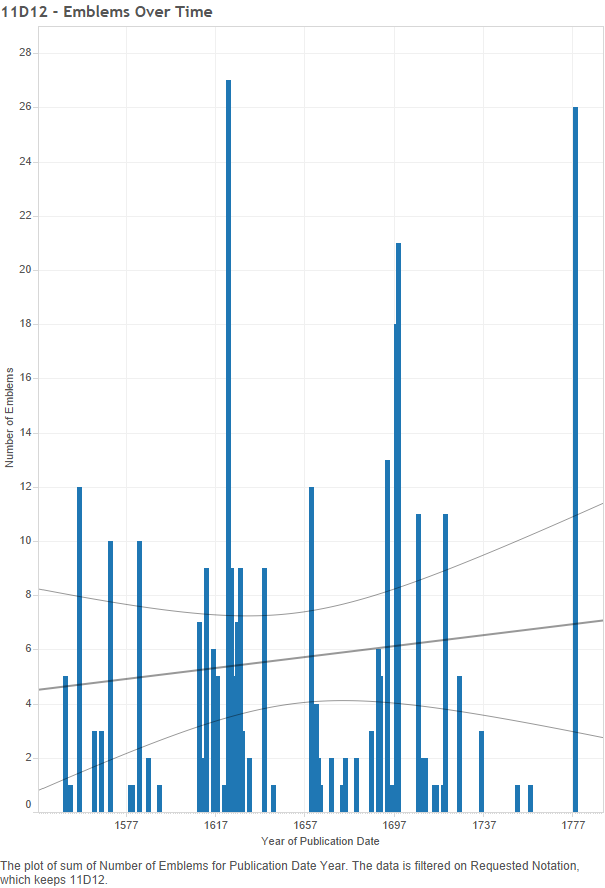
Figure 11 – 11D12: Number of emblems over time

Figure 12 – 11D326: Number of emblems over time
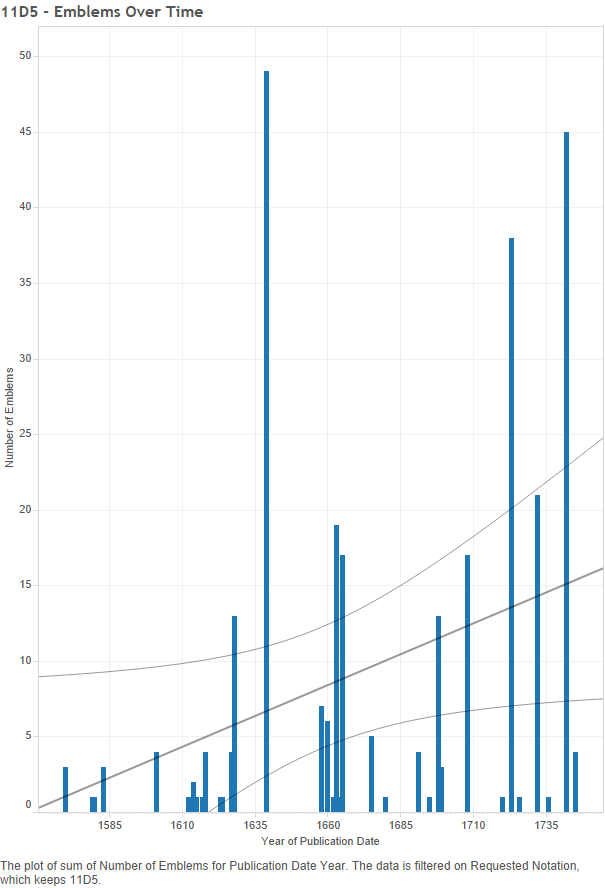
Figure 13 – 11D5: Number of emblems over time
These graphs show that the cross appeared in emblems from 1550-1778 (228 years), the fountain of life lasted 179 years (1563-1742), and signifiers referring to mystic ideas of Christ lasted 175 years (1570-1745). These three notations are among the longest lasting and they have no gap larger than exactly 20 years for 11D12, or 19 years for 11D326 and 11D5. Thus they seem to be the most frequently and consistently used, long-lasting ways of thinking of or indicating God/Christ within emblems.
Distribution in Language and Space
Those three notations are also among the symbols with the widest cultural distribution: emblems with “11D12 the cross” appear in nine languages, published in twenty-four different cities in eight present-day nations (plus one case where the location is unknown), emblems of “11D326” and “11D5” are in seven languages, from six different nations, published in fifteen and eighteen cities respectfully. In the bar chart below, the x-axis lists the number of languages used per notation (NOT per single emblem): 1 for unilingual, 2-5 for bilingual/moderate multilingual, and 6-9 for high multilingual. The height of the bars indicates how many notations have a certain amount of languages. So, for example, there are seven notations that have emblems published in five different languages (over the whole set of emblems, though certain emblems have multiple languages themselves).

Figure 14 – How many languages? (x-axis = number of languages; y-axis = number of notations)
Of these sixty-one symbols, the largest single group is made up of notations published in three languages; about one fifth of the notations. Thirty-five symbols (about 57%) could be considered to have reached a moderate amount of different lingual audiences, appearing in between two to five different languages. A smaller amount, eighteen symbols (about 30%), appear in books published in six or more languages; while only eight (about 13%) are published in one language only. It seems that translating emblems into other languages, and/or using two or more languages in a single emblem, was the norm. Given that most of the emblems appear in German, Latin and French (in that order, see Figure 1 above [or click here], which shows the number of emblems per language), it is unsurprising that those tend to be the top three languages for each notation.
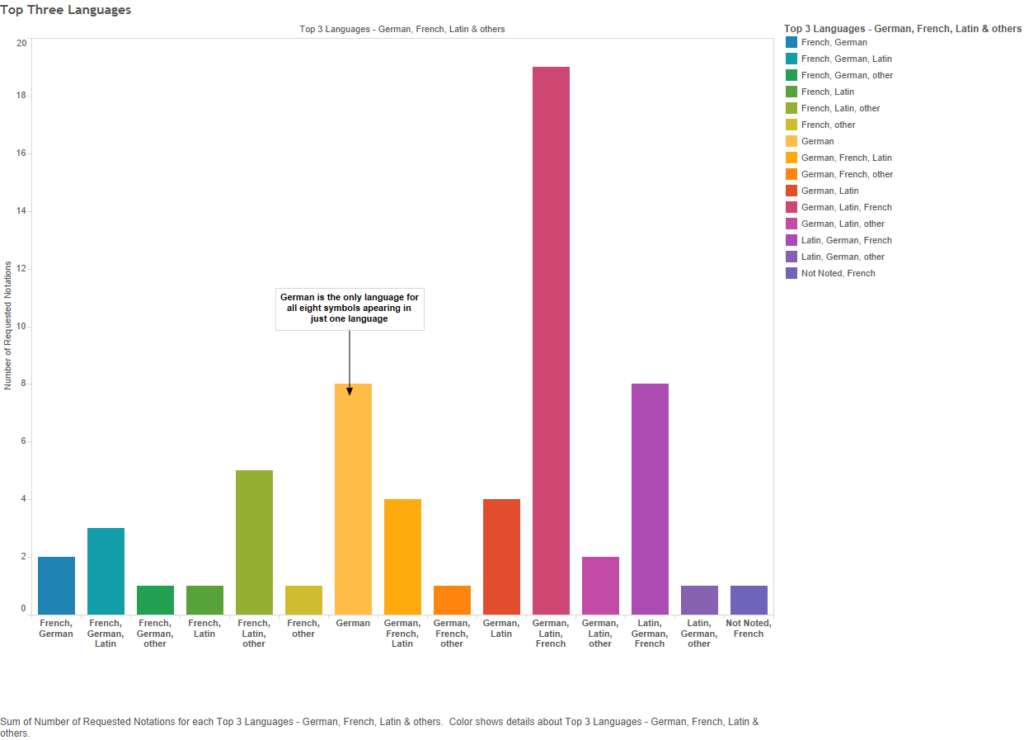
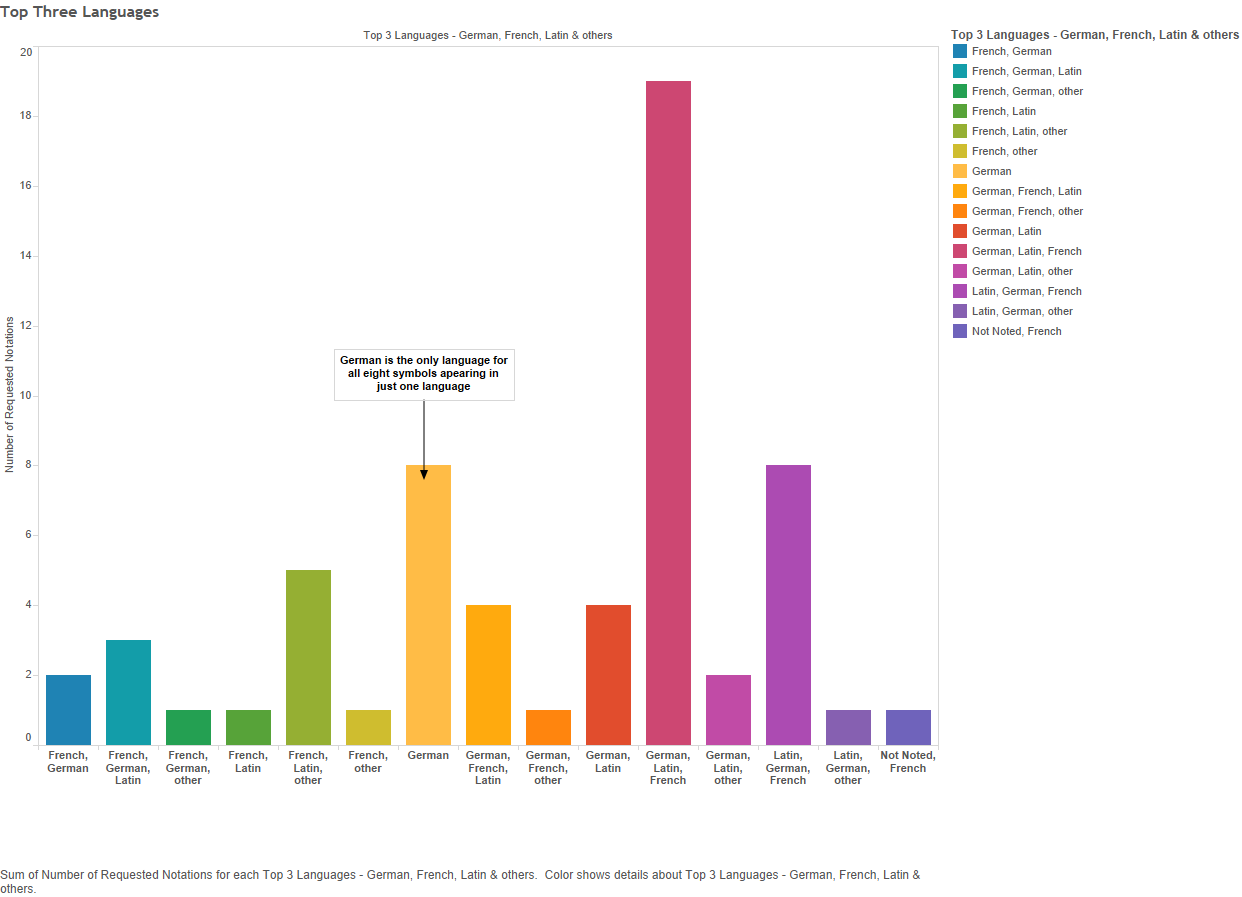
Figure 15 – Top three languages (x-axis = the top languages; y-axis = number of notations)
By top three, I mean the three most frequently used languages within the emblems marked-up with a particular God-symbol notation. For example, the top three for 11C1 are Latin (162 emblems), German (135 emblems) and French (82 emblems), which would place it as one of the eight notations in the purple bar, third from the right, in the above bar graph. Only eight notations (about 13%) do not have German as the first, second, or third most frequent language. German is the most frequent language for over 60% of the sixty-one god-signifiers. Additionally, German is the only language to be the sole language (thus the entirety of the blue bar in Figure 14, too).[2] In seven of the German-only notations, the emblem total is below 10, sometimes all appearing in the same book. However, “11D511 the Soul as bride of Christ” appears in 28 emblems, published in four different German cities (see below visualisation) in five different books.

Figure 16 -11D511: Number of emblems per publication location
So German, and to a lesser extent Latin and German, dominated the language of these emblems, perhaps affecting what symbols were prominent given each language’s intended audience(s). Still, the data shows that the God-symbols crossed linguistic boundaries more often than not, mostly to a moderate extent of two to five languages, with German, Latin and French almost guaranteed to be within the list, if not on top of it.
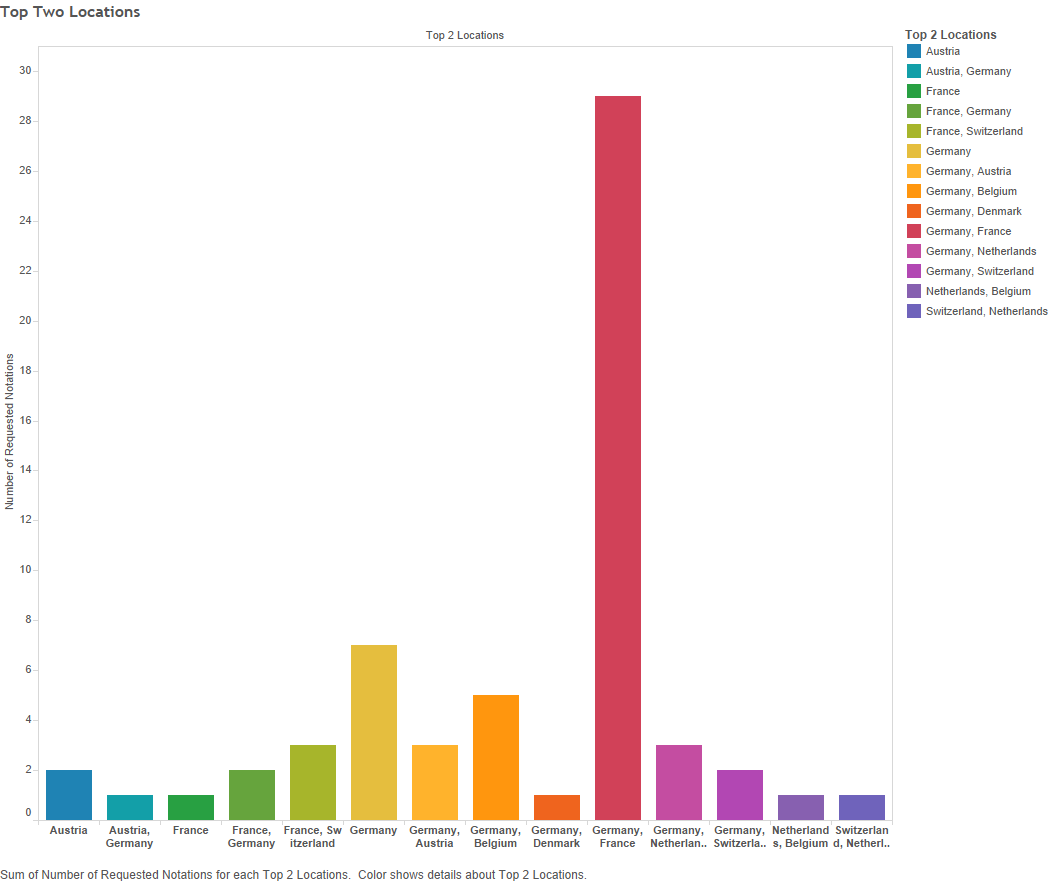
Different places: A similar picture emerges when looking at publication location. The below graph shows the top two frequent publication regions (x-axis), labelled according to present-day nations; the bar height showing how many of the sixty-one notations had emblems that were mostly published in those two (or sometimes one) region.
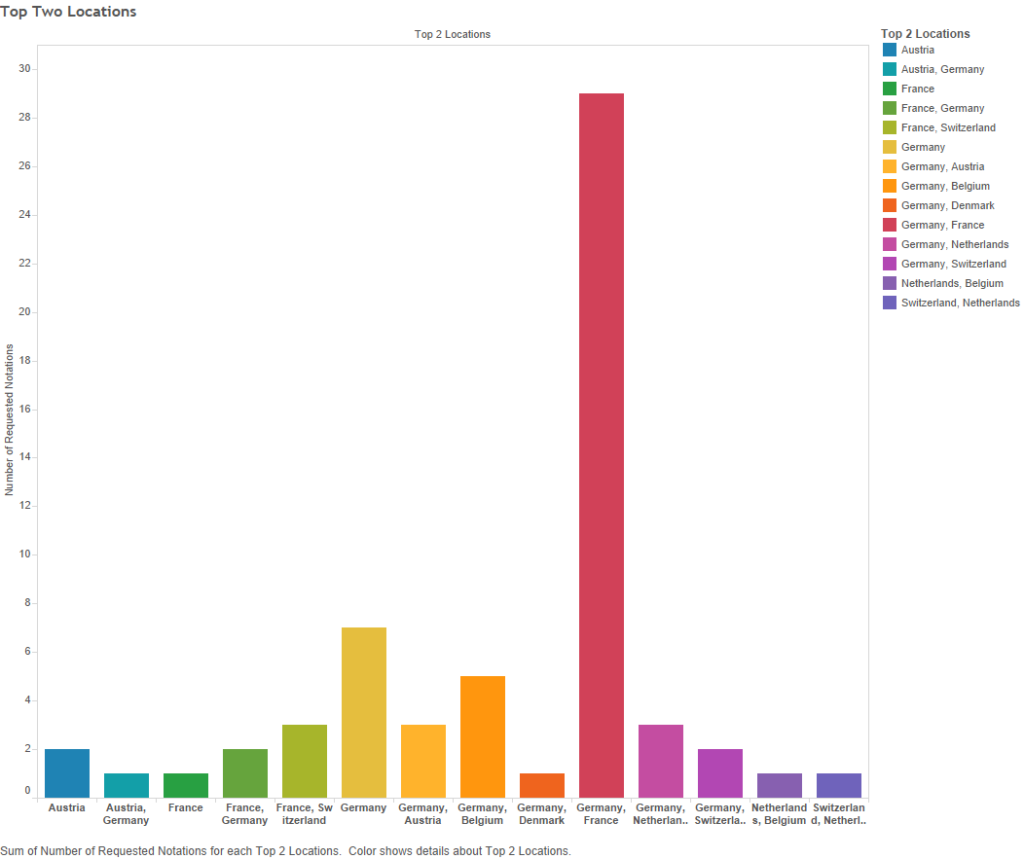
Figure 17 – Top two locations (x-axis = top locations; y-axis = number of notations)
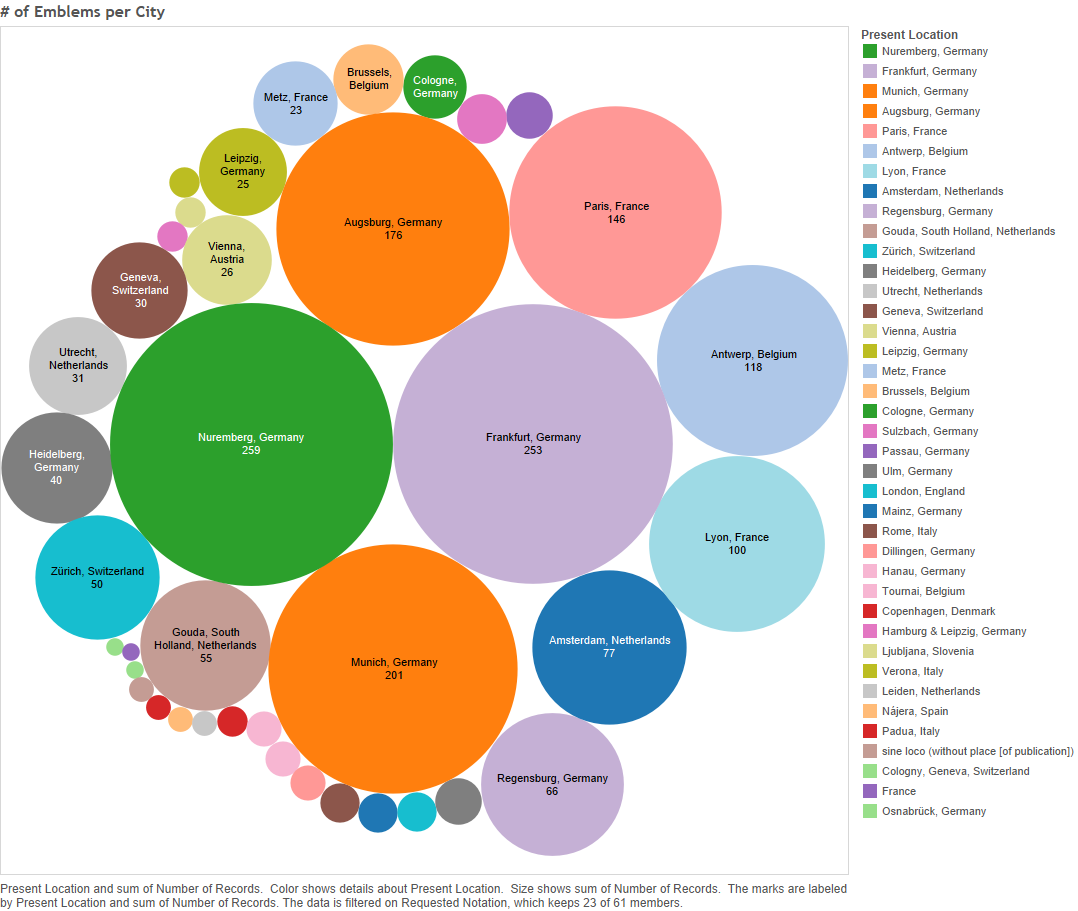
Frankly, Germany dominates. Out of sixty-one symbols, Germany is the most frequent publishing location for fifty of them. That is about 82%! For comparative purposes, France, is the most frequent present-day nation only six times (about 10%), and it is the closest to Germany in terms of total emblems published (see Figure 2 above, or click here).
However, while German cities pumped out more of these emblems than anyone else, the symbols, just like with language, do seem to spread across Europe, sometimes to a few regions, other times quite widely.
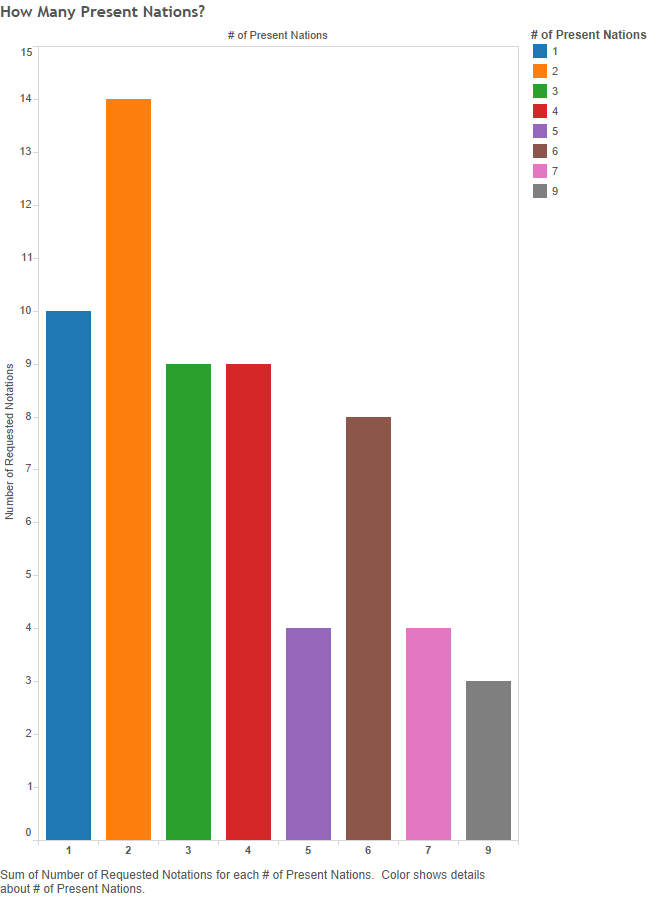
Figure 18 – How many present nations? (x-axis = number of different nations; y-axis = number of notations)
The numbers along the x-axis show how many present-day nations published emblems for a particular God-symbol (one to nine nations per single symbol), while the y-axis shows how many notations have emblems published in the given amount of different nations.[3] For example, the orange bar indicates that fourteen symbol categories include emblems published in two, and only two, present-day nations. Moderate spread (published in two to five nations) is the case for thirty-six out of sixty-one signifiers (about 59% of them). Wide spread symbols, those published in six or more nations, about 25% of the time (fifteen notations); and only ten emblem symbols stay within a single nation (16%). The situation is similar for cities:
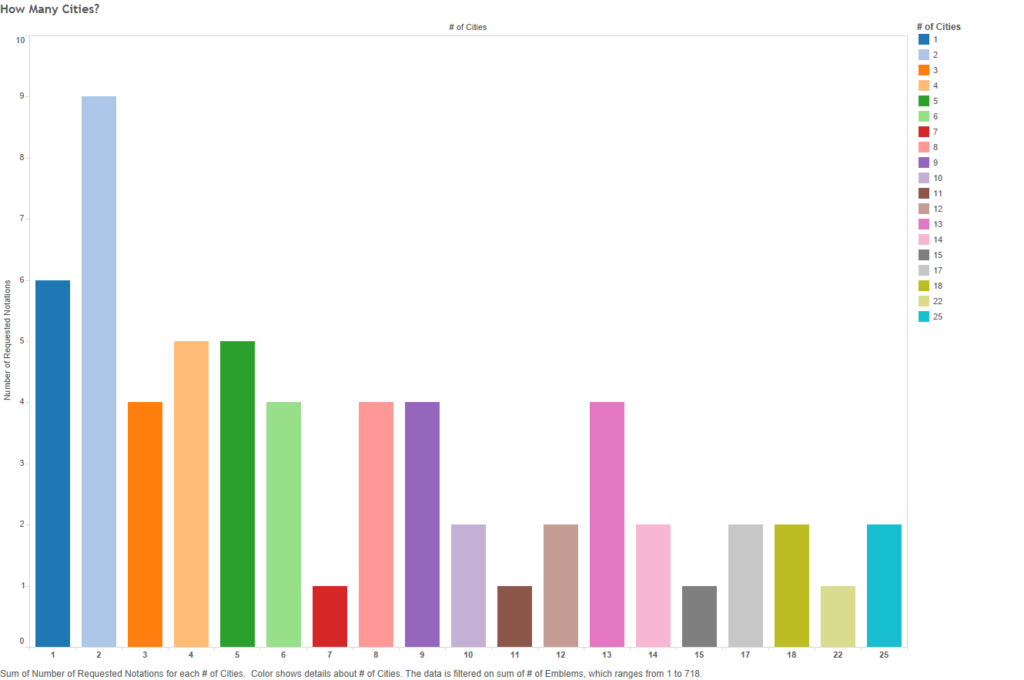
Figure 19 – How many cities? (x-axis = number of different cities; y-axis = number of notations)
As the above shows, twenty-three god-signifiers were published in two to five different cities (about 38%); fifteen were published in between six and ten cities (about 25%); about the same amount of signifiers spread wider, coming from eleven to twenty different cities; six symbols (about 10%) come from single cities; and even fewer (three notations, about 5%) are god-symbols so widespread as to appear in emblems from over twenty cities![4] Since there are sixteen German cities, compared to the next highest about – France with four cities – it is fair to assume that multiple German cities published emblems for most of the sixty-one notations.
While each of the notations, and the symbols or notions they represent, should be examined separately to see the extent of their cultural diffusion, one can still give an estimate for what seems to be the norm for this dataset. Using the averages of the data, the symbols seem to mostly be published in about four languages (avg.= 4.19) from locations in three or four present-day nations (avg.=3.67…), and in seven or eight cities (avg.=7.73…), some likely being German ones. However, the prevalence of Germany does not mean that the use of the emblematic symbols started there and then spread to other regions, in fact the opposite is just as plausible: that the symbols were first introduced to emblem books in other areas, say France, and were later used by Germans, among others. A different look is required.
Looking at the “Hand of God”
Two-hundred and forty-two emblems in this dataset are tagged “11C12 hand, ‘Dextera Dei’ ~ symbol of God the Father”. One example, the below image, shows the “Hand of God” (accompanied by the tetragrammaton) pointing at or touching the heart of a man.
![Figure 20 - Pictura from the emblem "FRVSTRA" by Georgette de Montenay and Anna Roemer Visscher. From the book Cent emblemes chrestiens [A Hundred Christian Emblems] published in Heidelberg, Germany in 1602.](http://aaronellsworth.ca/wp-content/uploads/2016/05/20.jpg)
Figure 20 – “FRVSTRA” by Georgette de Montenay and Anna Roemer Visscher. From the book “Cent emblemes chrestiens” [A Hundred Christian Emblems] published in Heidelberg, Germany in 1602.
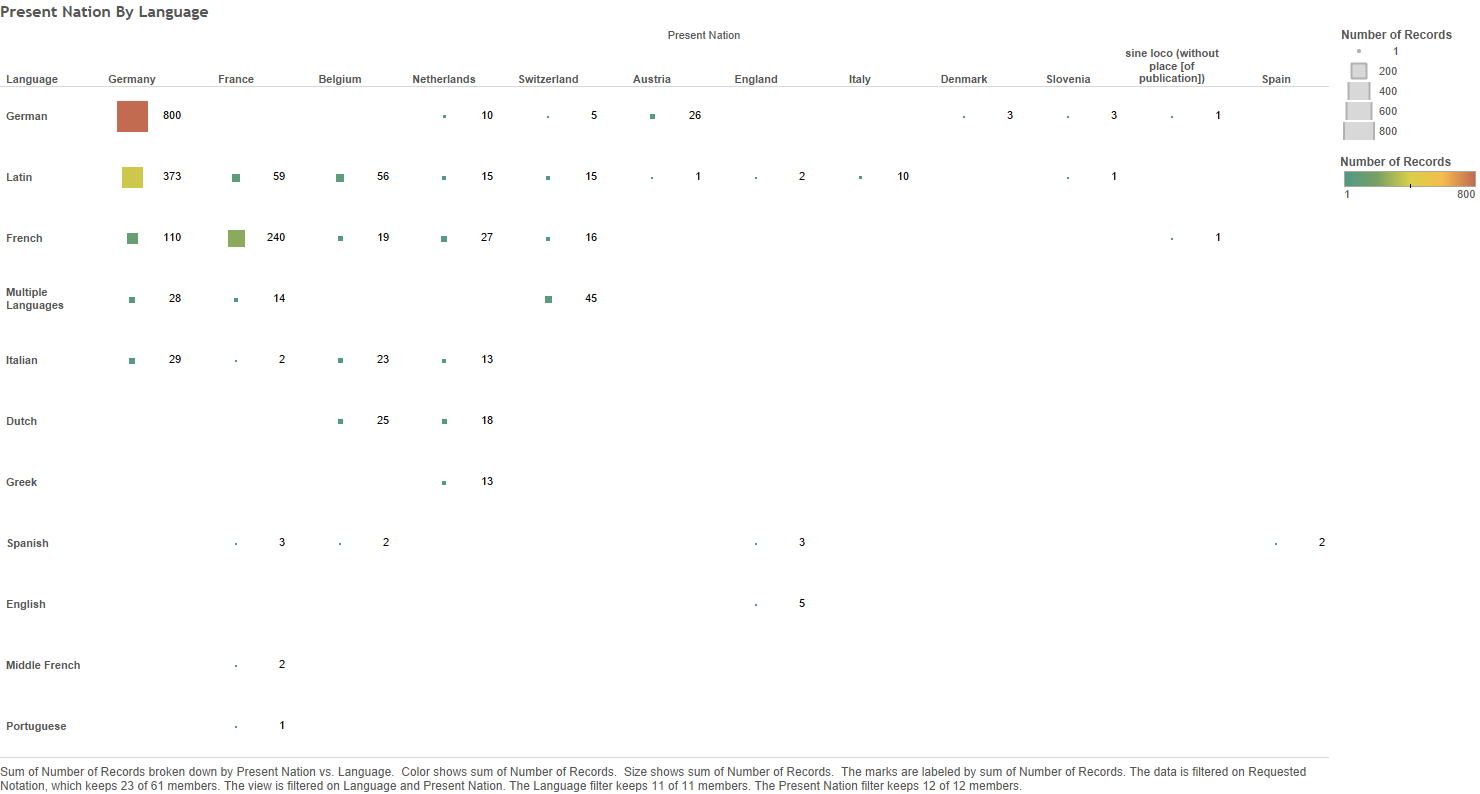
The Hand was culturally, widespread published in eighteen cities, representing six present-day nations – Germany (156 emblems), France (thirty emblems), Switzerland (twenty-six), the Netherlands (twenty-two), Belgium (seven) and Denmark (one) [see Figure 21 below] – and in at least six languages: Latin (ninety-two emblems), German (sixty-six), French (fifty-two), Dutch (three), Greek (three) and Italian (three) [see Figure 22 below].
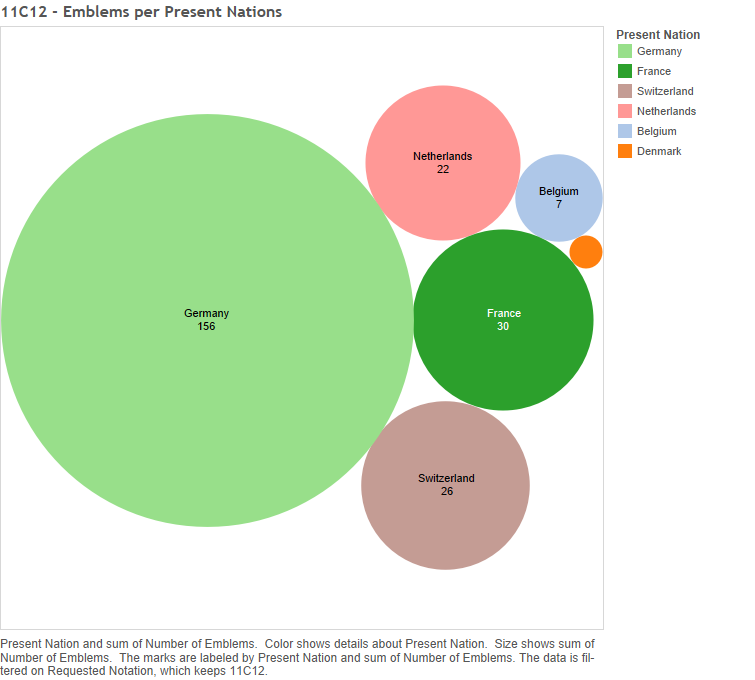
Figure 21 – 11C12: Number of emblems per present nations

Figure 22 – 11C12: Number of emblems per language
Over thirty were marked up as “Multiple Languages” without specification, and sixteen emblems had no language data at all. Emblems with the “hand of God” first appeared in 1550, and appeared off-and-on for 222 years, until 1772. Thus, this symbol lasted for almost the entirety of the genre’s popular period. Using Tableau, we can look at the movement this symbol made between languages and places.
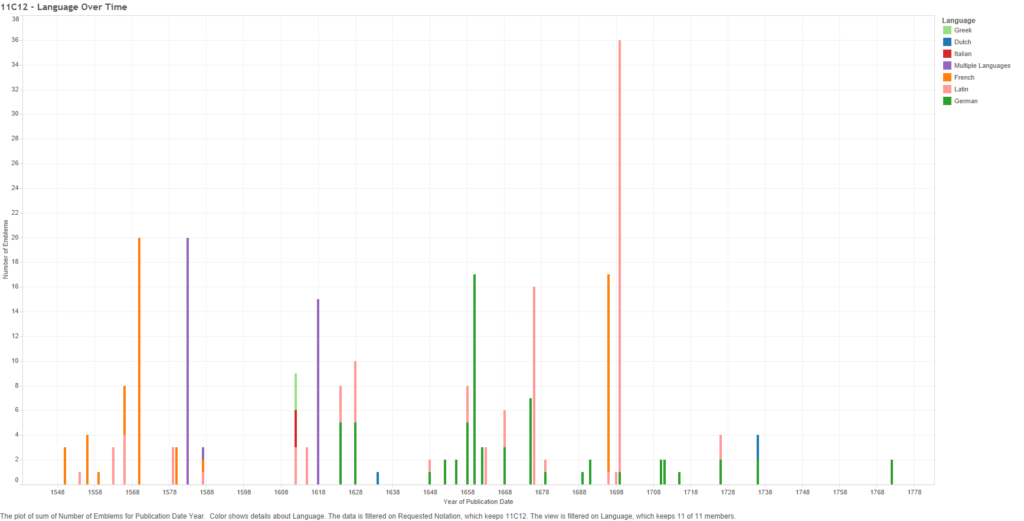
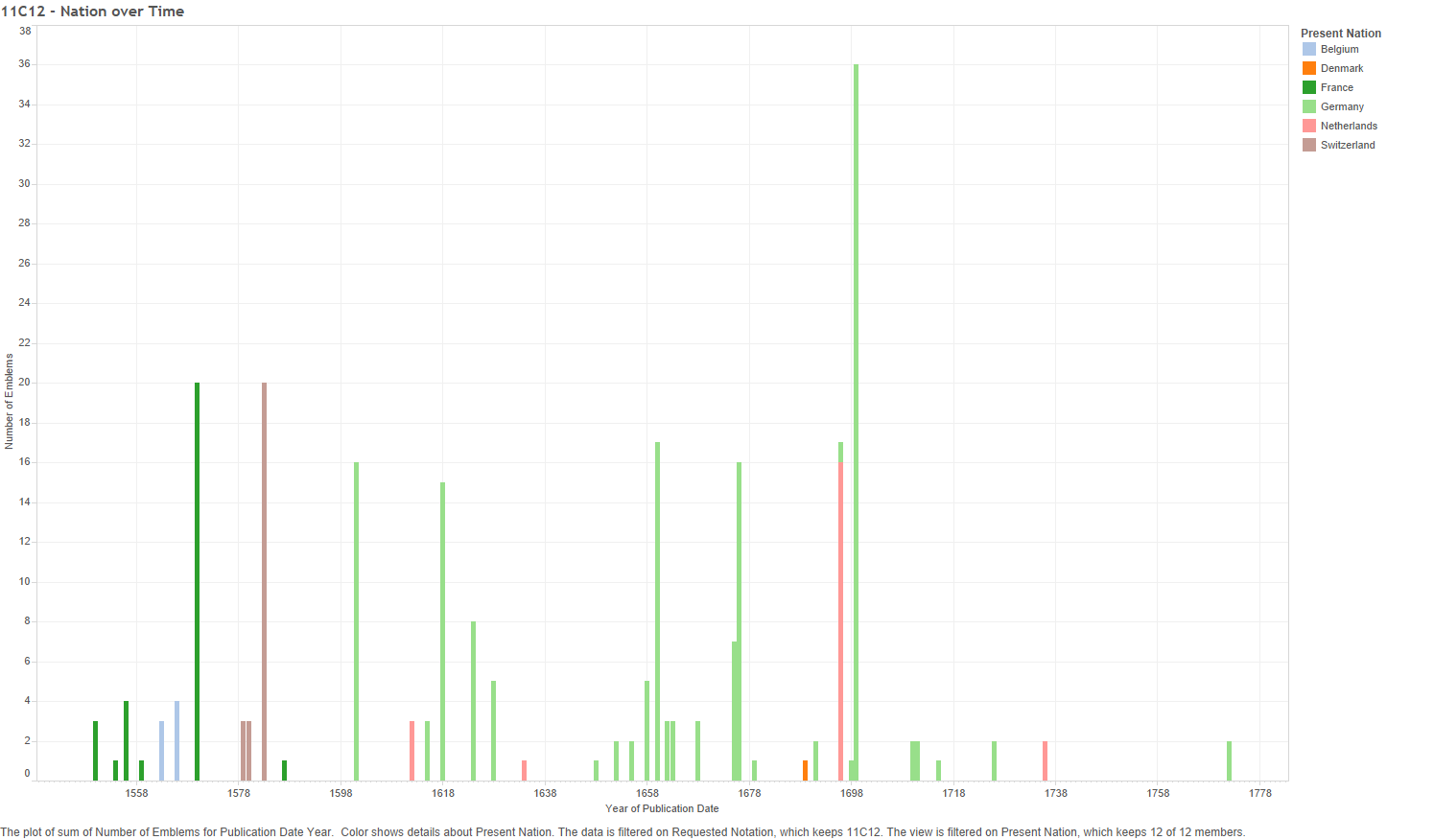
Figure 23 – 11C12: Number of emblems (Coloured by language) over time
The above graph shows the languages used in “Hand of God” emblems over time. Bars, rather than a line graph, are used to show the gaps where no emblems are present in the data, such as the twenty-five year gap around 1600. This graph shows a movement from French emblems (between 1550-1590) to predominately German emblems from the 1620s to the 1730s, with two more German emblems in 1772. Latin overlaps the other two languages, existing alongside the French emblems of the mid-late 16th century, then returning in 1612 in a set of three multilingual emblems (Greek and Italian being the other languages), and continuing into the German period. The amount of Latin “Hand of God” emblems explodes twice – sixteen emblems in one 1676 book, and thirty-five from a 1699 book – before petering out in the 1720s. Hypothetically, the solely Latin emblems are from the works of Jesuits (though that is not necessarily true), and the French and German emblems (with or without Latin mottos) are productions with a more Protestant outlook. A closer investigation of the individual creators’ religious outlook would be needed to prove such an argument. Still, the data does indicate a move by the symbol from French to German areas.
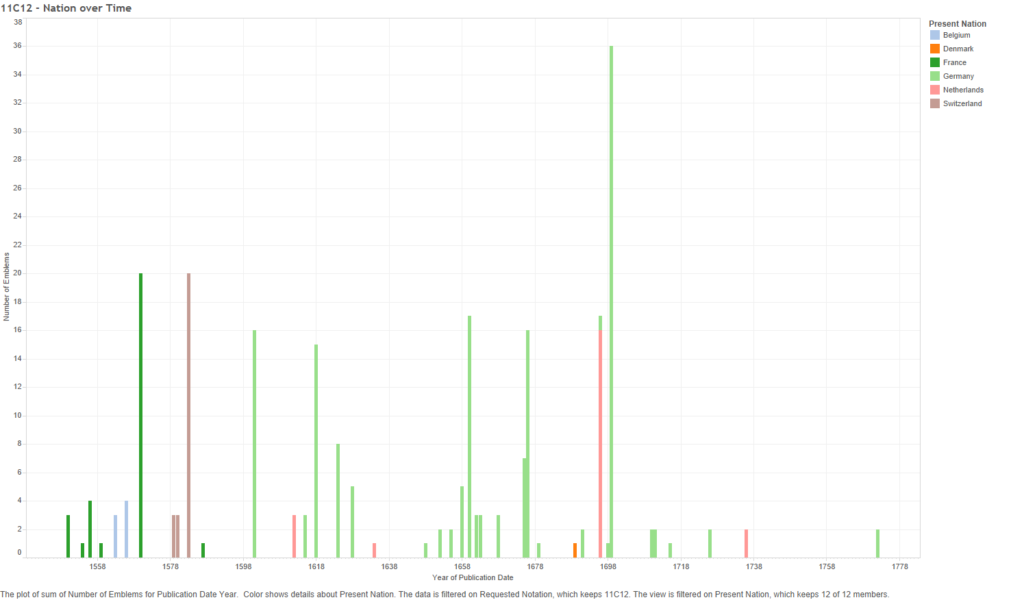
Figure 24 – 11C12: Number of emblems per nation over time
The above graph shows the 11C12 data for present-day nations; confirming the idea that emblem representations of the “Hand of God” somehow moved from French cities (in France and Belgium) to Germany. It also adds a few other facts, for example, that Switzerland was responsible for the multilingual “Hand of God” emblems from around 1580, and that the sixteen French emblems published in 1696 (see Figure 23), were published in the Netherlands, not France.
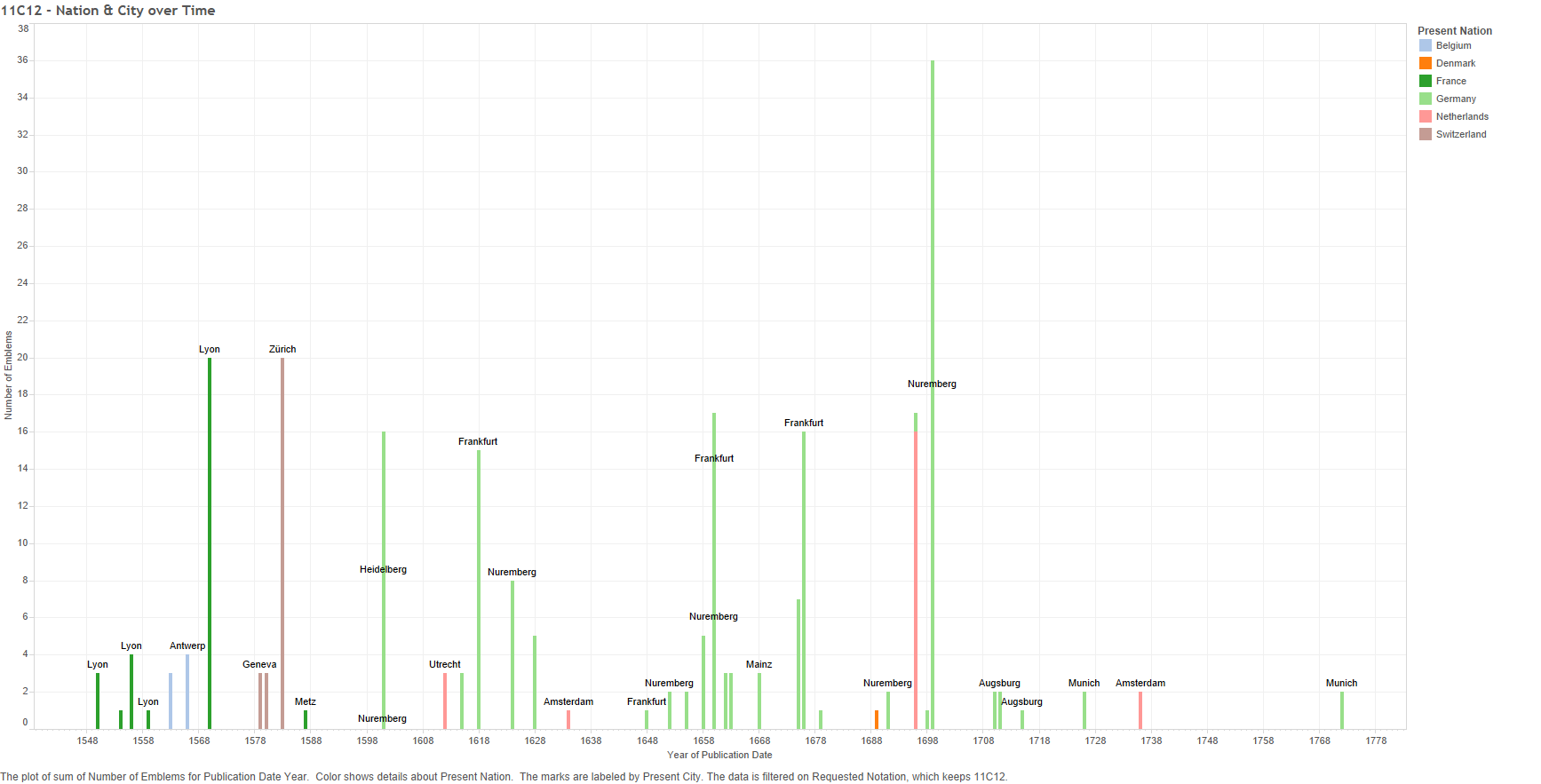
What caused the general move from France and Belgium to Germany and the Netherlands is harder to tell from the data alone, but the answer may be economic. Alison Saunders writes about French emblematists and publishers moving their operations from Paris to Lyon around the 1540s (416) and later to Antwerp (in present-day Belgium) in the 1560s and Leiden (the Netherlands) in the early 1600s (421-422).[5] My data follows this trend somewhat; the following graph is the same as the last one, except it adds the names of cities for most of the years.
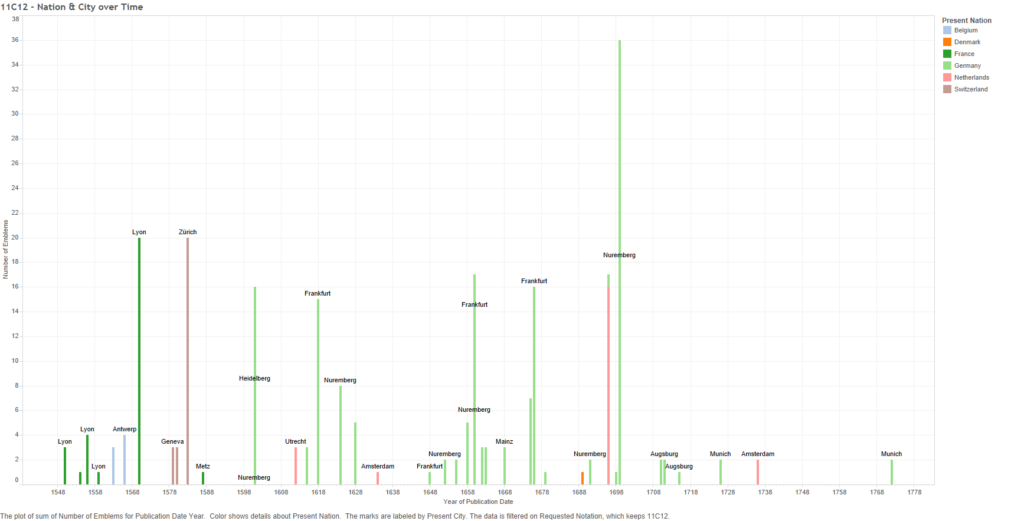
Figure 25 – 11C12: Number of emblems per location over time
Just as Saunders wrote, we start in Lyon after the 1540, with a move into Antwerp during the 1560s, though my data does show that emblems were still published in Lyon after. Likewise, “Hand of God” emblems first appear in the Netherlands in the early 1600s; just in Utrecht, and later Amsterdam, instead of Leiden. Saunders gives reasons for the moves; for example, Lyon in the 1540s was a cosmopolitan city, situated on trade routes and was a printing centre (416), thereby having ready access to a vaster European market. Similarly, Antwerp was seized upon for its access to the international market (421).[6] So one of the major reasons for the movement of this symbol from place to place was simply money. Saunders does not address the move into Germany, but perhaps economics may help explain that as well.
More historical research into the regions and the individual emblematists and publishers is needed to fully explore the reason for the spread of this symbol from the French to the Germans and other peoples. Perhaps that is one of the major strengths of such a distant reading of emblems using book-level bibliographic data, it entices curiosity. Whether looking at a single God-symbol, or the trends of a larger set, the data presents one with quandaries, practically begging the analyst to engage in further research to determine the causality behind the numbers.
Endnotes
[1] The tetragram, or tetragrammaton, is the four-letter representation of the “true name of God”, rendered YHWH in Latin letters. See McKenzie 1286.
[2] The eight notations that have solely German emblems are “11B12 Trinity represented as a person with three heads” and its subcategory “11B121 ‘Tricephalus’, three fused heads or faces only (~ Trinity)”; “11B33 representations of the Trinity” and its sub category “11B333 representation of the Trinity: symbol (Father), person (Son), dove (Holy Ghost)”, which I discussed earlier because all seven emblems showing this were published in one book in Vienna, Austria in 1681; “11D324 ‘Salvator Mundi’, [Savior of Man] making a blessing gesture; an orb in his hand or at his feet”; “11D328 types of adult Christ (alone)” and its subcategory “11D3283 Christ as angel”; and finally, “11D511 the Soul as bride of Christ”. All of the category-subcategory pairs include the exact same set of emblems.
[3] There is no bar for eight nations because there were not symbols published in exactly eight nations.
[4] Those three notations are “11C1 symbols of God the Father” (more of an abstract notion, or set of signifiers), “11C2 God the Father represented as human being, usually with crown or tiara or sceptre and/or globe” and “11D12 the cross ~ symbols of Christ”
[5] Saunders also mentions a return to publishing back in Paris in the 1650s by Catholic persons and groups (425-26), which are not reflected in my data. Perhaps those emblems have yet to be marked-up, or perhaps they did not use the “Hand of God” symbol.
[6] There was also “political unrest” back in Lyon (Saunders 421), which is a potential social reason for moving.
Works Cited
Aneau, Barthélemy. Imagination poetique, traduicte en vers François, des Latins, & Grecz, par l’auteur memse d’iceux. Lyon, Fr.: Macé Bonhomme, 1552. Emblematica Online. Web. 27 Apr. 2016.
—. Picta poesis. Ut pictura poesis erit. Lugduni [Lyon, Fr.]: Apud Mathiam Bonhomme, 1552. Emblematica Online. Web. 27 Apr. 2016.
Emblematica Online. University of Illinois Board of Trustees, 2015. Web. 25 Apr. 2016.
Knapp, Éva, and Gábor Tüskés. Emblematics in Hungary: A Study of the History of Symbolic Representation in Renaissance and Baroque Literature. Trans. András Török and Zsuzsa Boronkay. Tübingen, Ger.: Max Niemeyer Verlag, 2003. ProQuest ebrary. Web. 20 Apr. 2016.
McKenzie, John L. “Aspects of Old Testament Thought.” The New Jerome Biblical Commentary. Ed. Raymond E. Brown, Joseph A. Fitzmyer and Roland E. Murphy. London: Novalis, 2011. 1284-1315. Print.
Montenay, Georgette de, and Anna Roemer Visscher. Cent emblemes chrestiens. Heidelberg, Ger.: Johann Lancelot, 1602. Emblematica Online. Web. 27 Apr. 2016.
Saunders, Alison. “French Emblem Books or European Emblem Books: Transnational Publishing in the Sixteenth and Seventeenth Centuries.” Bibliothèque d’Humanisme et Renaissance 61.2 (1999): 415–27. JSTOR. Web. 20 Apr. 2016.
Sucquet, Antonius. Andächtige Gedancken zur Vermeidung des bösen und Vollbringung des guten aus dem Buch Weeg des ewigen Lebens. Wienn [Vienna, Aus.]: Voigt, 1681. Emblematica Online. Web. 27 Apr. 2016.

Finding God in the Metadata: Distant Reading and Emblem Studies by Aaron Ellsworth is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.